When being used, corporate information systems accumulate large amounts of information highly valuable for companies. At the same time, it turns out that the number of incorrect values and invalid or incorrectly presented data grows together with the amount of data.
There are several main causes of such problems:
- Invalid data entered by operators or users if there are no validity checks in information systems or standard software used in the company or these checks are incomplete.
- Internal bugs in software processing or transferring data.
- Low-quality data import from other formats or from sources outside the company without any checks or with low-quality checks.
Other causes are also possible, but they occur relatively rarely (for example, deliberate input of invalid data) and we will not take them.
|
"Dirty" data in databases may make the work of the company considerably more difficult, garble statistics and have a negative effect on decision-making processes. Data Clearing Process EstablishingThe process of improving the quality of data can be divided into two steps: data analysis (or audit) and cleaning (when invalid data is modified or removed from a database). We will take two main types of invalid data: integrity violations and presentation errors. Here is a more detailed description. Integrity violation means errors connected with the relation
of one data item with others in the same or some other table, row or database.
|
 |
In most cases, it is possible to avoid such errors if the database is designed with all data peculiarities taken into account. In practice, it is impossible to foresee all problems beforehand. Also, it is not always that the DBMS used in the company has all tools necessary to ensure data integrity. The performance issue also matters: if data is mostly correct, it is better to load a large data array with disabled checks first and then clean the data.
Presentation errors occur only in text fields because any DBMS controls data presentation for fields of other types and their external presentation depends only on the client application. Usually, problems of this type occur in typified strings that must have an internal structure: phone numbers, addresses, codes, etc. Actually, these are internal integrity problems, unlike external integrity problems of the first type.
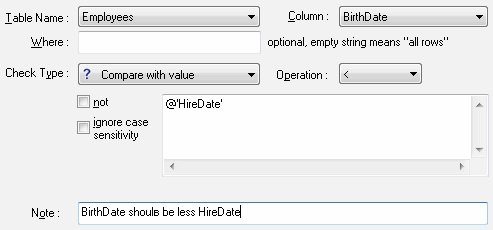
So, let us move over to working with invalid data. We will start from audit. To audit data, you should describe the correct data presentation and also integrity requirements applied to it. Thus, rules describing all fields that need to be audited are created in DTM Data Scrubber.
The program analyzes these rules, goes through all values present in the database and compares them to the requirements. If some data does not meet the requirements, a record about the field and the table that has a problem is added to the report.
It is obvious that for the audit there should be only one rule describing data presentation, while there may be several integrity rules.
Each rule in the program can contain a small note, which makes its use more visual. Rules are specified in a project which is saved to a separate file. One project may contain both audit and clearing rules, the program applies them independently.
The program offers three options while executing a project: apply all active rules of one type (audit or clearing) from the project, apply only those rules that are selected in the list or apply only one rule highlighted by the list cursor. The last two options make project development easier.
Let us now proceed to the description of data cleaning rules. Unlike in audit rules, it is possible to specify any number of presentation rules for each field because they work according to another mechanism. The program selects all rules from the list for the field being processed and checks if any rule matches the data in the field. If no rule matches, the field is considered correct. If some rule matches the data (the value is not correct), the program can perform a corrective action. We will describe them later. Let us take an example to explain this mechanism: suppose a database has only one field with an alphanumeric sequence, but users occasionally enter extra spaces before it. We describe a rule that defines a field format with one or several spaces before the sequence (regular expressions described below serve this purpose best) and specify the operation of replacing the value with the substring of the initial field that corresponds to the sequence without spaces. Once the program comes across a field with spaces, it will prepare an update SQL statement for data correction.
Built-in Data Checks
|
The program can perform the following checks:
What operations can the program perform if a field matches a rule? Firs of all, it is replacing with a constant or expression (only for matches with regular expressions). Besides, you can change the value of a field to NULL. The second variant is convenient when the field contains some garbage and it is impossible to extract any useful values from it. |
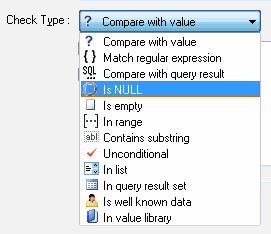 |
There are two extra actions that enable searching for a substring:
replacing the first match and replacing all occurrences of a substring to the user-defined value.
In the process of cleaning data, a rule can be either terminate or not. Terminate rules stop
checking the current field in case they come across a match, while other rules continue
checking. It means that several actions can be applied to one field if non-terminate rules are used.
Search and Replace with Regular Expressions
Let us see in detail how the mechanism of searching and replacing with regular expressions works. We will not describe their syntax in detail because you can find it in the product help and on specialized resources, but we will give small explanations.
In the process of comparison, the program fills internal variables \1, \2, etc. with values that coincide with a substring of the regular expression in brackets. These variables can be used as part of the text for replacement.
Let us take the example described above (with extra spaces before the value of the field). A sequence of digits and uppercase letters consisting of one or more characters is described by a regular expression as [0-9A-Z]+
Let us put it in brackets for the value to get into the variable and add the description of one or more spaces and tab characters before it: ^[ \t]+([0-9A-Z]+)
So we get the expression meaning the following: at the beginning of the string there are one or more spaces or tab characters followed by a sequence of uppercase letters and digits. Note that during the comparison this sequence will get into variable \1. If you specify \1 in the replacement variable, leading spaces and tabs will be cut off, which is what we need.
Let us take the following example: suppose some database field contains phone numbers. The program processing these fields expects that the field will have the format (NNN) NNN-NNNN, but in practice the field may contain values in the following presentations: NNN NNN-NNNN, NNNNNNNNNN and NNN NNNNNNN, as well as invalid data that does not match any of the given presentations. Our task will be to bring all data to one format and to replace garbage with the value (000) 000-0000.
To solve this task, we will create one rule for the correct presentation, three rules for incorrect presentations and one rule for invalid numbers. We will specify "nothing" as the action for the first rule and replacement with a regular expression as the action for other rules. Note that all rules will be of the terminate type, i.e. if the program finds a matching presentation, the value is not processed further. It is needed for values processed by previous rules not to get into the "all the rest" rule.
So, our regular expressions for rules will look like this:
- \([0-9][0-9][0-9]\) [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9] pay attention to \( and \) - brackets are shielded so that they are processed not as part of regular expressions, but as characters
- ([0-9][0-9][0-9])( [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]) in this case brackets are used to fill variables. We select replacement with (\1)\2 as the action for this rule
- ([0-9][0-9][0-9])( [0-9][0-9][0-9])([0-9][0-9][0-9][0-9]) note that in this case there are three pairs of brackets already - there will be three variables that are used as (\1)\2-\3 during the replacement
- ([0-9][0-9][0-9])([0-9][0-9][0-9])([0-9][0-9][0-9][0-9]) this case is practically the same as the previous one and we use (\1) \2-\3 (pay attention to the space) as the replacement string
- The last expression will be .* - it is any set of characters. We use our typified string as the replacement.